llama를 도입하게 되었고 llama 를 원하는대로 커스텀하는데 꽤나 애를 먹었기 때문에 개발일지를 작성할 겸 설명서를 작성해봅니다
Meta의 llama는 Meta 홈페이지에서 llama를 다운로드 하려고 하면 한국은 다운로드 대상 국가가 아니지만 오픈소스이기 때문에 구할 수 있다면 (ex. Meta 홈페이지 내의 협력사 사이트 ) 사용해도 무관하다.
현재 ollama 사용법의 블로그는 많지만 EC2 인스턴스 까지의 과정이 상세히 작성된 블로그를 보기가 힘들어 작성합니다.
ollama를 이용해 llama를 구동하고 EC2 인스턴스에서 구동하는 방법을 알아보자.
일단 ollama를 다운 받는다.
Download Ollama on macOS
Download Ollama for macOS
ollama.com
ollama의 명령어는 다음과 같다
| ollama serve | ollama 실행 |
| ollama list | ollama에서 사용할 수 있는 모델 목록 |
| ollama run model | model 자리에 실행할 모델명을 넣으면 실행된다 |
| ollama rm model | model 자리에 삭제할 모델명을 넣으면 삭제된다 |
| ollala pull model | model 자리에 pull할 모델을 넣으면 다운로드한다 |
| /show info | 현재 실행중인 모델 정보를 확인 |
- ollama serve 실행시 아래와 같이 에러가 발생하는 건 이미 실행중인 경우입니다.

그 후 원하는 모델을 다운받아서 이용한다. 파일은 GGUF파일로 구하면 된다. 난 허깅페이스에서 모델을 찾았다.
목적은 번역이기 때문에 번역으로 2차 훈련이 된 한국어 번역 전용 모델을 찾았고, 용량을 줄이기 위해 Q4 양자화 모델을 찾았다.
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M
MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M · Hugging Face
Update! [2024.06.18] 사전학습량을 250GB까지 늘린 Bllossom ELO모델로 업데이트 되었습니다. 다만 단어확장은 하지 않았습니다. 기존 단어확장된 long-context 모델을 활용하고 싶으신분은 개인연락주세요!
huggingface.co
GGUF 파일 만 있으면 되기 때문에 GGUF파일만 별도로 다운 받은 후, 동일한 경로에 파일을 하나 새로 생성한다.
VScode에서 파일을 생성하면 된다.
FROM Llama-3-Open-Ko-8B-Q5_K_M.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. 모든 대답은 한국어(Korean)으로 대답해줘."""
PARAMETER temperature 0
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>
temperature 는 모델의 대답의 창의성을 띈다, 나는 매번 번역의 결과가 변하는걸 원하지 않기 떄문에 0으로 설정하였지만 의역이 필요할때는 소숫점 단위로 올려줘도 된다.
num_ctx 는 AI모델이 응답을 생성하는 컨테이너의 사이즈이다, 위 링크의 모델은 512 모델이지만 한번에 더 많은 text를 번역하기를 원하기 떄문에 4096으로 설정하였다.
FROM 의 자리에는 내가 받은 파일의 이름을 설정한다.
해당 파일을 Modelfile이라는 이름으로 저장한 후 동일 경로 선상에서 cmd를 켠 후 다음 명령어를 실행합니다.
ollama create -f Modelfile llama-3-korean
llama-3-korean 자리에 원하는 이름을 넣으면 앞으로 해당 이름으로 모델을 실행하게 됩니다.
이제 ollama list로 내가 작성한 모델이 생성되었는지 확인 해 보자
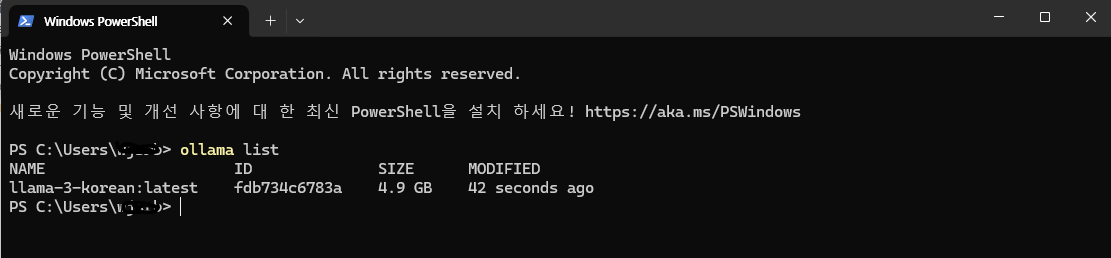
ollama run model을 사용하면 다음과 같이 작동합니다
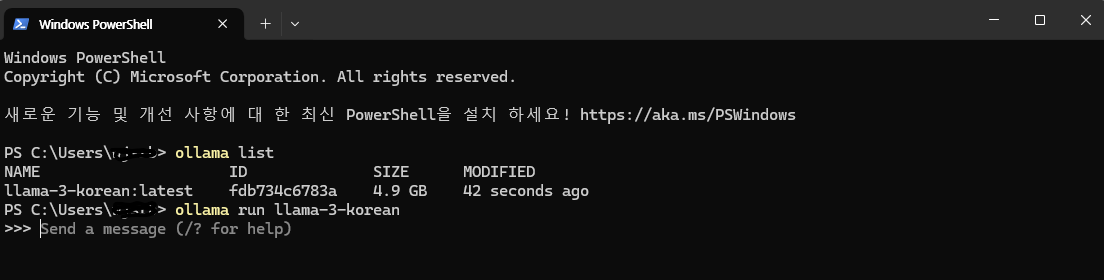
send a message 가 출력되면 llama 가 정상적으로 작동하는 겁니다!